Processing Twitter Data with Kafka Streams
Recently, we gave a talk at SAP on Kafka and the surrounding ecosystem and created a small project to demonstrate how easy it is to set up a stream processing architecture with Apache Kafka - no Hadoop necessary. We do of course love Hadoop and all surrounding projects, but for small-ish endeavors the overhead of setting up an entire cluster can sometimes be a bit daunting and might be overkill. In this post I will describe how we set up the demo and explain a few of the decisions and thoughts behind the architecture. For those of you that want to set this up and have a play with it for themselves I will also mention where to get the relevant pieces of code and what to do with them as we go along.
The idea for this demo is to read tweets from the Twitter api and perform some basic stream processing on them to extract buzzwords that are frequently mentioned. The central element for this will be Kafka as a message queue, all data is either written to it (referred to as publish), retrieved from it (involving a subscribe), or both (forming a publish-subscribe, or pubsub, system), a strategy loosely following the Kappa architecture - which started out as a technical quip, but has since gained traction as a term.
Architecture and Components
Let's take a look at the individual components involved in the setup.
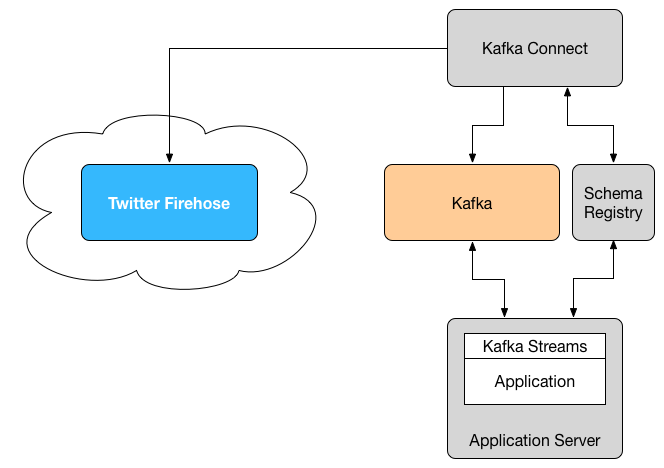
Kafka is a distributed message queue and used to transmit persisted data in topics. It is central to the data flow in this project. As mentioned, Kafka follows the pubsub principle, where clients are responsible for both writing and reading messages. This frees the design from unnecessary dependencies, and allows for easier scalability.
Kafka Connect is a lightweight tool that can be used to move data into and out of Kafka. It can either be run in standalone mode as a single process, but also offers a distributed mode which allows for load balancing the workload across multiple servers.
Kafka Streams is a Java library published by Confluent and offers stream processing functionality that tightly integrates with Kafka as a data source and target. The crucial difference to other streaming solutions is that it has no active component, or external process. In fact, Kafka Streams runs completely in application code and imposes no change in the cluster infrastructure, or within Kafka.
Schema Registry is a shared services that catalogues and tracks serialization schemas used with Kafka topics. This allows for both publisher and consumer instances to verify that all messages send or received are valid in regards to a known schema. Applications using the provided classes will have their schemas, provided as Avro structures, automatically registered and versioned.
Setting it up
As prerequisites to run the demonstration code you need to have Kafka, Kafka Connect and the Schema registry set up on your computer (or a virtual machine). All of these components are provided by Confluent as part of the Confluent Platform, which is the easiest way to get up and running quickly.
You can follow the quickstart guide which will give you everything you need to proceed. Alternatively OpenCore provides a virtual machine that you can use as basis for all further steps. The VM is defined in a Vagrantfile, so you will need to install Vagrant to use it. To start the machine, simply run the following commands:
$ git clone git@github.com:opencore/vagrant-confluent-platform.git . $ vagrant up
Getting data from Twitter is handled by a Kafka Connect twitter connector, you will need to build this according to instructions on the GitHub page and customize two configuration files that are included as examples in the repository. The following list the two files and the main options to look out for:
In
connect-source-standalone.propertiesyou need to modify the following:# Set this parameter to the connect string for one or more of your Kafka brokers. bootstrap.servers=http://localhost:9092 # These parameters need to be set to your schema registry url key.converter.schema.registry.url=http://localhost:8081 value.converter.schema.registry.url=http://localhost:8081
In
twitter-source.propertiesyou need to modify the following:# The name of the Kafka topic to write the messages to topic=test # Configure your twitter api credentials below twitter.consumerkey=... twitter.consumersecret=... twitter.token=... twitter.secret=... # You will also need to uncomment at least one of the options below to define which tweets you are interested in # language=en,ru,de # stream.type=sample # stream.type=filter # track.terms=news,music,hadoop,clojure,scala,fp,golang,python,fsharp,cpp,java # San Francisco OR New York City # track.locations=-122.75,36.8,-121.75,37.8,-74,40,-73,41 # bbcbreaking,bbcnews,justinbieber # track.follow=5402612,612473,27260086
Then start the connector with:
$ connect-standalone connect-source-standalone.properties twitter-source.properties
You should now see Twitter data coming into the topic you specified in the configuration (default is test if you did not change it). The next step is to start the Kafka Streams job that processes this raw data into our word count. You can find the code and instructions for running it at https://github.com/opencore/kafkastreamsdemo
Using it
Once the above is running, the following topics will be populated with data :
- Raw word count - Every occurrence of individual words is counted and written to the topic
wordcount(a predefined list of stopwords will be ignored) - 5-Minute word count - Words are counted per 5 minute window and every word that has more than three occurrences is written to the topic wordcount5m
- Buzzwords - a list of special interest words can be defined and those will be tracked in the topic buzzwords - the list of these words can be defined in the file buzzwords.txt
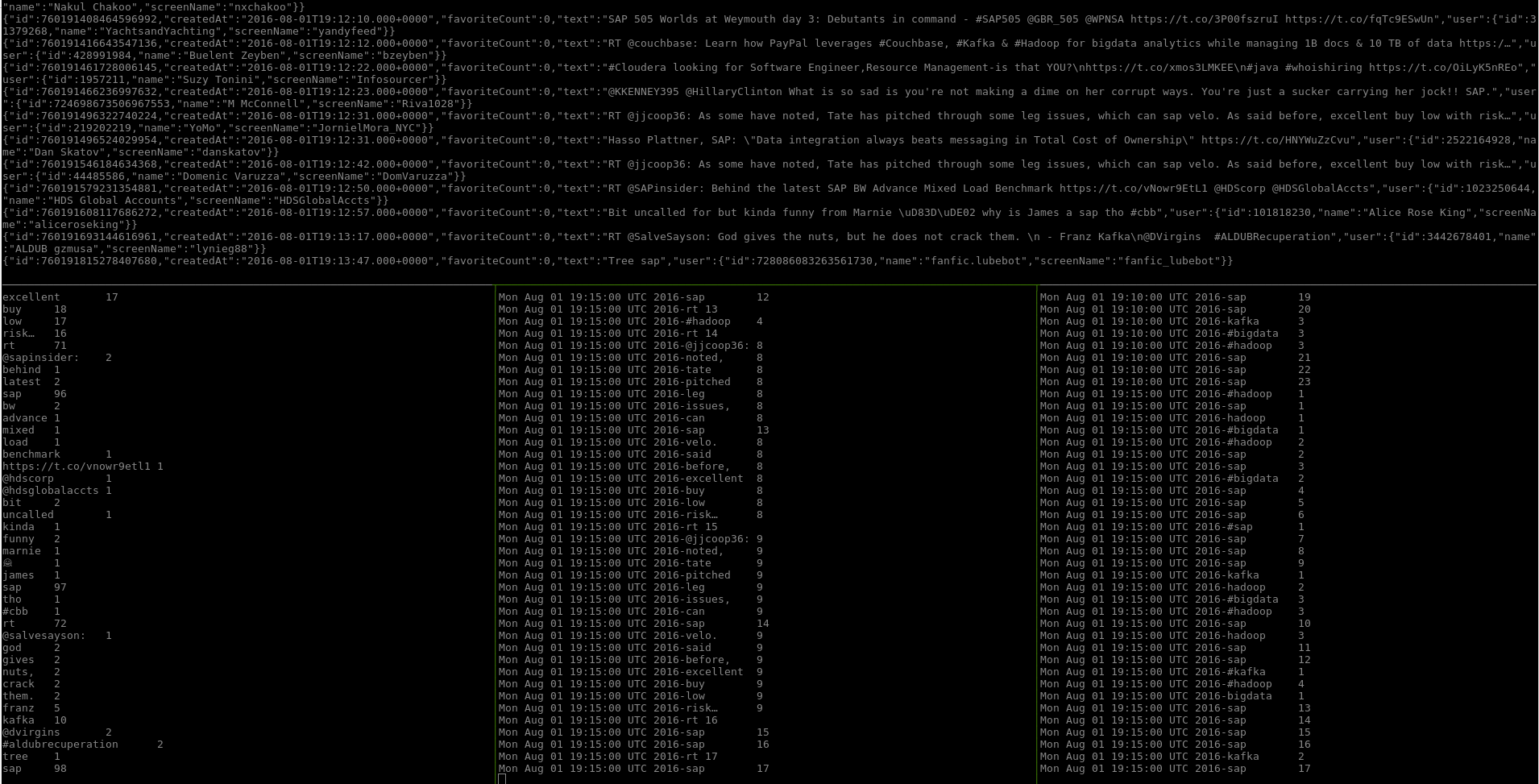
The screenshot shows these three topics at the bottom from left to right, while at the top you can see the twitter input feed. In this example we fed a Twitter stream that was looking for the keywords "sap", "kafka", "opencore", and "bigdata" into the stream processing engine and looked for the same words as buzzwords. As you can see SAP is still fairly dominant on twitter, but there are a few mentions of the other buzzwords as well.
On your test system you can use the following command to check the topics:
$ kafka-console-consumer --topic _topicname_ --new-consumer --bootstrap-server 127.0.0.1:9092 --property print.key=true
Have fun trying it out and as usual, if you have any questions, give us a shout, we are always happy to help!