Introduction to SAP Vora
SAP Vora
Update 2018-02-13: Since this blog post has been initially published SAP has released Vora 2.0. SAP has also released SAP Data Hub (https://www.sap.com/products/data-hub.html). Data Hub is a new product which aims to solve the Data Integration & Orchestration problems for SAP customers with a focus on Big Data technologies. Vora is now part of this offering and SAP has stopped marketing it as a standalone product.
If you're following this blog, we assume that you know what Hadoop and “Big Data” is. When you're thinking about the Big Data landscape lots of vendors come to mind (Cloudera, Hortonworks etc.). One vendor that you might not immediately connect with this world is SAP. For those who don't know: SAP is the third largest (according to Wikipedia) software engineering company in the world. Their product portfolio is mostly centered around applications to manage business operations.
They do however have multiple products that in fact are related to the Hadoop ecosystem:
- SAP Vora
- SAP BusinessObjects Lumira (BI)
- SAP Cloud Platform Big Data Services (formerly known as Altiscale)
- SAP HANA (In-memory database & much more as I recently learned)
- SAP Data Services (Data Integration & Data Quality)
These are just the ones I could find but I'm sure there's more.
And because that's the case we're excited to focus on one of these tools today: SAP Vora. We recently had the chance to sit with the Vora team and pick their brains and learn what it is and what it's not. (Full disclosure: We worked with SAP recently on a paid engagement and took this opportunity of access to the Vora team to look further into the details of SAP Vora).
The Name
SAP Vora used to be called SAP HANA Vora which lead to all kinds of confusion as to the relation between SAP HANA and SAP HANA Vora.
Fortunately, SAP has made this clear in March 2017 (with the release of Vora 1.4) by officially renaming it to SAP Vora.
To sum it up: SAP Vora does not rely on SAP HANA but they two can work together.
What is it?
Having gotten that out of the way let's dig into what Vora actually is and does.
SAP quietly released Vora 1.3 in December 2016 which featured major improvements over the previous 1.2 version. In March 2017, they released version 1.4 (which also changed the name). This blog post is based on version 1.4.
If you're confused by all the different tools in the Hadoop ecosystem, then Vora won't make it easier for you. On last count, it consisted of 14 different components that need to be installed. But there’s an installer that takes care of that for you!
In summary Vora is a tool that you install on all your Worker nodes (we'll go into more detail later) in your existing Hadoop cluster (CDH, HDP and MapR are all supported including installation via their Cluster Management tools). This starts a process on each machine that's going to run permanently. There is no consistent naming for this process. The documentation calls it V2Server, Vora Worker, Vora In-Memory Engine and Vora Execution Engines but we've been told the component should be called the "In-memory relational engine" but because that's a bit tough to spell out each time I'm going to call it Vora Worker. This is in contrast to e.g. a MapReduce or normal Spark application but similar to Impala or Hive's new LLAP module.
Currently you access this engine via a Spark extension (based on Spark 1.6.x). Instead of using a normal SparkContext or SQLContext you're using SAP's SapSQLContext which is a drop-in replacement for SQLContext.
That's all that's needed to get you started. You can now use Spark as you would without Vora. If you normally create a Dataframe in Spark and register it using registerTempTable (or createOrReplaceTempView as of Spark 2.0.0) this table is tied to the current SQLContext (or SparkSession in Spark 2). That means this metadata along with all cached data will go away when the Spark app stops for any reason. Currently the only way to work around this in Spark is by using the Hive metastore to store catalog information and then on startup connect to it and read the data.
Using the Vora extensions you can register a table in the Vora Catalog (or Catalog Server, the documentation uses both names) which itself uses the Vora Distributed Log (or DLog) to persistently and securely store the table metadata. That means you can just load tables from the Vora Catalog when you start a new Spark Session instead of recreating the metadata from scratch.
What Vora now does is load the underlying data from HDFS, S3, Swift or the local filesystem into memory distributed across all those Vora Workers and keeps it there. That means if you now use Spark SQL (which Vora also extends, more on that in a bit) this SQL is sent to another component called Transaction Coordinator which uses code generation with LLVM (like some other SQL-on-Hadoop solutions) to generate optimized code to run this query and distribute the work amongst the worker nodes. These worker nodes now run this query against the data they have in-memory and return it.
So, in some regard it is like other SQL-on-Hadoop tools as it specializes in very fast access and processing of data in various sources. It is also similar that it is not a general-purpose processing engine like for example Spark or MapReduce but limited to certain query types (more on that in the next section). Where it’s different is that Vora always loads, and keeps all data in memory while Impala for example always reads data from the source systems. In addition, Vora does more than just plain SQL as we’ll see next.
To sum it up: Your main access point to Vora will be through Spark which provides you with DataFrames to work on your data. There are layers on top of this that can abstract the low-level details away for you (like the HANA integration, see below, or tools like Lumira).
Engines
Vora 1.3 brings support for the so-called "engines". These engines are specialized for their specific use-cases:
- Time-series
- Graph
- Document store
- Disk engine
- Relational
The latter is the traditional SQL accelerator I've described above, which has existed in some form since the beginning of Vora as a product. Before the 1.3 release there was only the relational in-memory support. 1.3 added support for multiple engines and 1.4 deprecates the old “standalone” relational in-memory support and adds it back as an engine. This might sound confusing but makes a lot of sense because the Disk engine and the Relational engine share their syntax and features and now they have feature parity while in 1.3 there were discrepancies in features and how to use them.
All the engines apart from the Disk engine store and keep their data in memory. The relational engine does have a mechanism (as of Vora 1.4 it’s properly documented but I think it did exist in 1.3 as well) to swap data to disk at the cost of performance. The disk engine only lifts data to memory for processing and drops it again afterwards.
Time-series Engine
As the name implies this engine is optimized to store and analyze time-series data. There is (to my knowledge) not a lot of competition in the Big Data field here. There is OpenTSDB but it has a different focus. For one thing OpenTSDB does not expose SQL based access to the data. It is more an optimized TS storage solution than a processing or analytics engine. OpenTSDB has only very limited functionality for more than the most basic retrieval operations.
This is one example of a table definition using this engine:
CREATE TABLE name ( ts TIMESTAMP, value1 INTEGER DEFAULT NULL, value2 DOUBLE ) SERIES ( PERIOD FOR SERIES time START TIMESTAMP '2010-01-01 00:00:00' END TIMESTAMP '2010-12-31 00:00:00' EQUIDISTANT INCREMENT BY 1 HOUR ) USING com.sap.spark.engines;
This creates a table called name with a time-series with equidistant points at an interval of 1 hour. You can now use more SQL to actually query the data:
SELECT TREND(val1ue) FROM SERIES name WHERE PERIOD BETWEEN timestamps '2010-09-01 00:00:00' AND timestamp '2010-10-01 00:00:00'
It has support for lots of options like compression of time-series, getting histograms, partitioning and much more. As this is brand new in 1.3 I'm sure there's much more to come. Currently it supports CSV based data only.
This is (for me personally) the most interesting of the new engines as a lot of today's use-cases are based on time-series data. Be it IoT or clickstream data or any other kind of events (most of the current Kafka use-cases). And there is currently no SQL based engine tied into the Hadoop ecosystem that does these kinds of things.
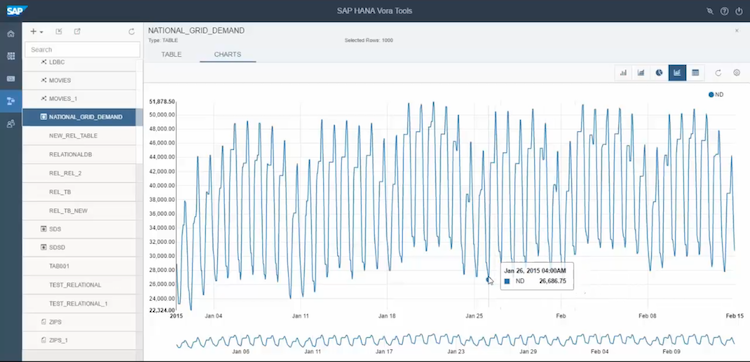
Graph
The Graph engine allows to run graph operations (e.g. degree, distance) on data stored in Vora. Graphs in Vora consist of Nodes and Edges. Nodes have a type, optional properties and incoming and/or outgoing edges. Edges only have a type and cannot have properties. The documentation contains an example using Actors and Movies.
This data must be specified in a so-called JSG file. JSG files are line-based JSON files, where each line contains a full JSON record. Unfortunately, that also means that you'll have to convert your existing data into this format to use it.
The following SQL snippet is one example on how you’d create a Graph table in Vora. This one is backed by a file called movies.jsg in HDFS:
CREATE GRAPH MOVIES USING com.sap.spark.engines OPTIONS ( files 'movies.jsg' storagebackend "hdfs" );
That's how you create a graph table in Vora and this would be how to query it:
SELECT M.TITLE FROM MOVIE M USING GRAPH MOVIES WHERE DEGREE(IN M)>1
The result of this query would be a list of all movies that have more than one connection to other movies.
While Spark has its GraphX package it does not (to my knowledge) support a rich SQL based query language (and sees very little development).
Document store
This is a document-oriented, JSON based, SQL database. MongoDB comes to mind as a comparative product but MongoDB does not natively support SQL while Vora does.
The source data needs to be JSON files with one JSON document per line as is common in the Hadoop world.
CREATE COLLECTION T USING com.sap.spark.engines OPTIONS ( files 'path/to/file/to/load/some.json' storagebackend "hdfs" );
The data can then be queried using SQL. Nested data can be accessed using the point notation:
SELECT address.street FROM customers WHERE address.country = 'Germany';
Disk engine
This is another new addition in Vora 1.3 and you can think of it as a data access accelerator. Version 1.3 had the limitation of only being available on a single node. Version 1.4 lifts this restriction and the features are now on par with the relational in-memory engine. You can load data from your data sources (e.g. HDFS) and push it into the disk engine (which in fact is a columnar relational store). As you can imagine querying data from an optimized data store is faster than reading and interpreting data from a (possibly remote) data source.
Possible use-cases I can think of here are lookup or dimension tables that need to be accessed often in joins and which should be available fast but don't necessarily fit into or need to live in memory all the time.
It's going to be interesting to see where SAP takes this engine in the future.
UI
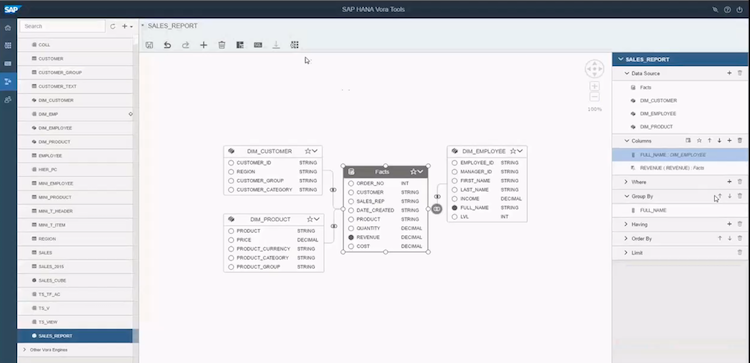
As mentioned before you can access Vora from Spark. But you can also use the Vora Modeler UI. That is a web based graphical user interface that allows you to model and query data.
This is something that is currently missing in the popular Hadoop distributions. Hue and the Ambari Views have something similar to some degree but the Vora Modeler UI has a graphical way to create tables and queries which is very nice.
SAP HANA Integration
This post wouldn’t be complete without mentioning that Vora can obviously talk to HANA and the other way around. The integration is seamless. Please note that the implementation details changed between earlier releases (like 1.2) and 1.4 and the information presented in this post is only valid for 1.4 and newer.
There’s two directions to talk about. Accessing data that currently lives in HANA from a Spark context (and potentially pull some of it in one of the Vora engines) and accessing data that currently resides in Vora from HANA.
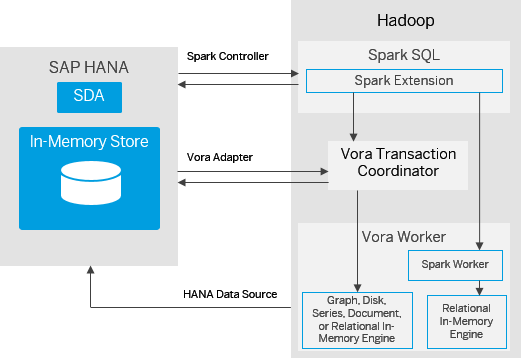
Accessing HANA from Spark
This direction is super-easy to use. For details also check out the documentation. This direction is implemented as a Spark Data Source and as such can be easily used for example from within SparkSQL. Here’s sample code from the documentation:
CREATE TABLE $tableName USING com.sap.spark.hana OPTIONS ( tablepath "$tableName", dbschema "$dbSchema", host "$host", instance "$instance", user "$user", passwd "$passwd" )
This registers an existing HANA table for use in further Spark SQL queries. This way you can also create new tables in HANA and use all the existing Spark functionality. That’s pretty neat.
Accessing Vora from HANA
I don’t know nearly half as much about HANA as I do about Spark so I hope the following is correct. But to my understanding there are two ways you can access Vora.
Remote source - voraodbc
You can create remote sources in HANA which connect to other non-HANA data sources. Vora does provide one such source in an adapter called voraodbc. In HANA, you can do this in a statement like this:
CREATE REMOTE SOURCE <Name> ADAPTER "voraodbc" CONFIGURATION 'ServerNode=<TC Server>:<TC HANA Wire Port>;Driver=libodbcHDB' WITH CREDENTIAL TYPE 'PASSWORD' USING 'user=my_user;password=my_password';
The TC Server mentioned there is the Transaction Coordinator of Vora.
Spark controller
The old way used to be something called a Spark controller. This is a Spark process running on Hadoop on behalf of HANA that HANA connects to to get data not only from Vora but also from Hadoop itself. So, it is a bit more general purpose than the voraodbc version but it also doesn’t perform as well and uses more resources. SAP recommends using the new voraodbc version.
Deployment & Testing
If you just want to test Vora you can download a free single node developer edition as a virtual machine or run an instance on AWS. You’ll find the links and documentation on the Vora site. These require registration.
For real deployments, you have the option of deploying it on-premise or in the cloud. For the latter part the easiest choice will probably be through the recent acquisition of Altiscale. SAP can host a fully managed Vora instance for you in their Big Data Services offering.
Use-cases
Okay, that's what Vora is and contains. When and where would you use it?
Well the answer is: It depends on your own use-cases, SLAs and needs but here are some examples:
- One trend we're currently seeing with our customers is that data is prepared in Hadoop (using any of the myriads of tools that are available) and then pushed out to an in-memory database (e.g. Exasol or SAP HANA) for serving to customers. This is something that you could use the in-memory relational engine for. The good thing is that it can combine the processing and serving steps if needed.
- Scalability is another important issue. Hadoop and Vora are both designed to scale basically infinitely and also run on commodity hardware.
- There are a few options for storing and processing Graph data in Hadoop but none of them are wildly popular and none are supported by all vendors (e.g. IBM ships Titan [now reborn as JanusGraph], others include Spark but don't support GraphX). Using the Graph engine, you now have a way to store and process graph based data.
- Using the time-series engine you can process sensor data for example for predictive maintenance or alerting scenarios.
- You now have all these different engines in one integrated product without having to go for multiple separate ones. The Document store covers NoSQL engines like MongoDB which are not even part of the typical Hadoop distributions.
What's missing/Drawbacks
I won't lie: Vora is interesting but as with any new solution there's also a few important features missing yet and there are a few drawbacks.
- An authorization model is currently missing but planned for a release in Q3 this year
- Another one -- that it has in common with for example Impala -- is the static partitioning of resources. That means you'll have to carve out some resources from your cluster and reserve it for Vora. It does not integrate with the resource management that YARN brings to the table.
- To make access fast the Vora Thriftserver has a Spark app constantly running. This takes up additional resources on the cluster even when it's not being used.
- There is currently no AD/LDAP integration for the Vora Modeler.
- No integration with the Hive metastore.
- No support for complex types (structs, arrays, map).
Pricing
Unfortunately, I don't know much about pricing and the little I do know I'm not allowed to share. I suggest you talk to a SAP representative. As far as I know Vora is licensed by the number of production worker nodes you have (so dev & test environments are free which is very nice and different from other Hadoop vendors, management and master nodes are also free). There are two licensing models available: Subscription and perpetual.
Summary
I hope I could give a quick technical rundown of what Vora is and what you can use it for. At the moment, some of its features in early stages but promising. As far as I know nothing like this exists in the Open Source world so it can be a very good entry into the Big Data world and might certainly be easier to use than to use three or four different and separate components (e.g. Neo4j for Graph, OpenTSDB & HBase for Time series, Impala or Hive LLAP for faster SQL processing etc.). For existing SAP HANA users, the added benefit is also that Vora can be used to make available Hadoop based data for querying in HANA and vice versa, thus allowing to integrate Big Data environments seamlessly into existing business systems.
It will be very interesting to see how SAP will drive Vora in the market in the coming years, especially with non-SAP customers.
Questions?
If you do have any technical questions around Vora please don't hesitate to leave a comment and I'll try my best to answer them. Any business-related question I'll probably have to forward to someone at SAP but feel free to leave a comment as well.
All images used with permission from SAP.